The Power of Data@Factory
Go beyond de-identification – link records to create a complete view of the therapeutic experience
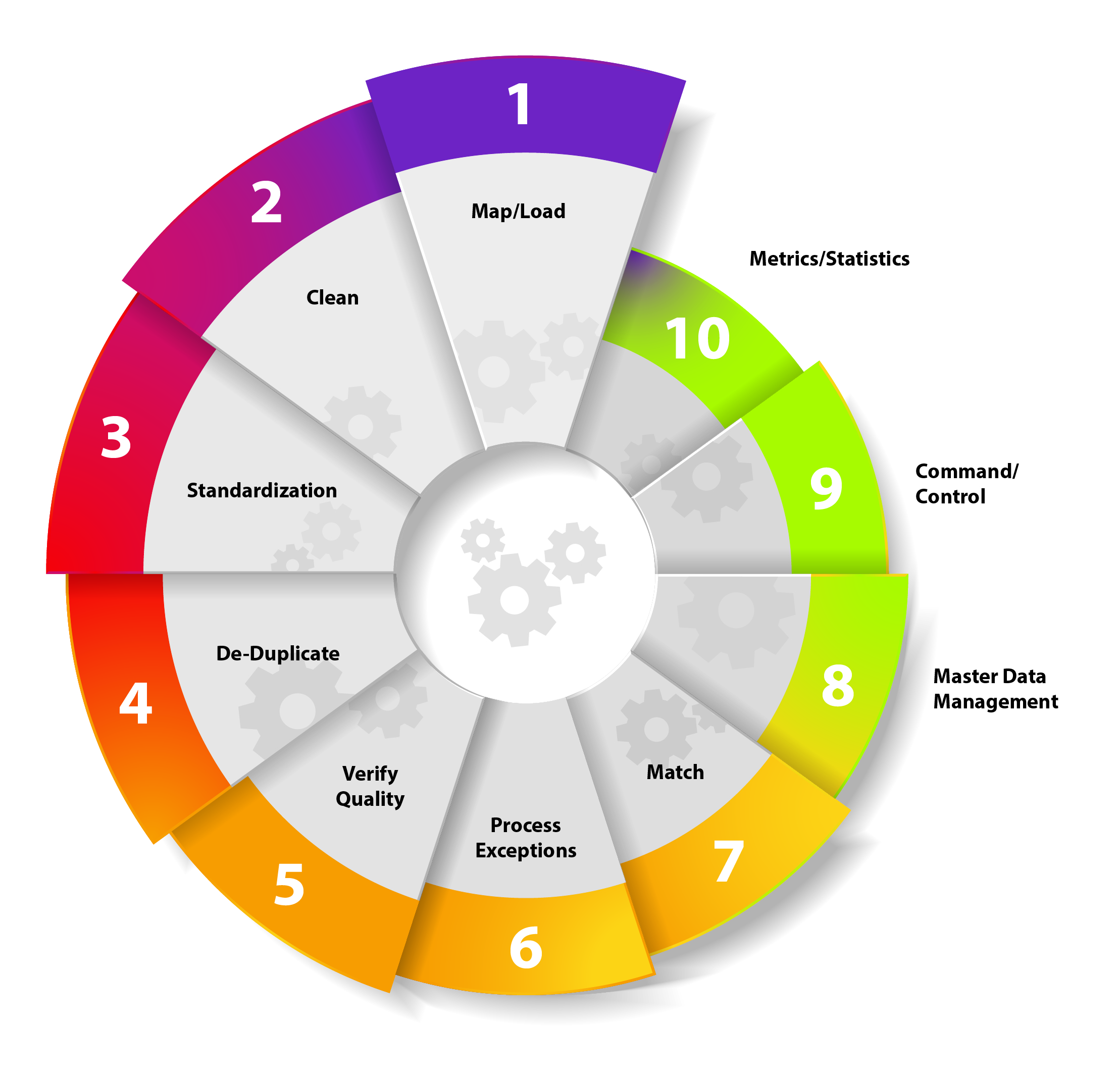
MSA’s patented, industry-agnostic Data@Factory technology addresses the rapidly growing need for HIPAA-compliant solutions that provide integrated, anonymous data for sophisticated patient-centric analytics.
Data@Factory transforms raw disparate data from across the healthcare spectrum – including but not limited to pharmacy, medical, and hospital claim data – into connected information.
Adhering to each customer’s specific business rules, de-identified data is processed through the Data@Factory for robust patient matching. The Patient Matching process assigns an anonymous Patient ID – that’s as strong as using PHI but without the risk – and creates and maintains an anonymous Patient Master table to enable the longitudinal alignment of the disparate data from multiple data sources.